به قلم: عرفان فرهادی، بنیامین قاسمینیا
مقدمه
حدود یک سال از جشن فارغالتحصیلی دانشجویان ورودی ۹۴ و خوشیهای آن روز میگذرد. در کنار همهٔ عکسها، کلیپها و خاطراتی که به یادگار ماندهاند؛ دفترچهای هم به عنوان یکی از اصلیترین یادبودهای این مراسم تهیه شده بود که محتوای آن نوشتههایی بود برای دوستان. در سایتی که برای جشن فارغالتحصیلی تهیه شده بود؛ هر فرد میتوانست برای هر دیگری یک یادگاری بدون محدودیت تعداد کلمه بنویسد. از آنجا که این یادگاریها به صورت عمومی منتشر شدهاند با هماهنگی مسئولین این جشن بر آن شدیم تا کمی با این مجموعه دادهٔ کوچک ولی گویا دادهورزی کنیم و به چند سوال ساده در فضای اجتماعی دانشکدهمان و ارتباطاتمان با کمک این دادهها پاسخ بدهیم.
هر کدام از ما در طول دوران دانشجویی با تعدادی از همدورهایها دوستیم و احتمالاً برای همین دوستان هم یادگاری مینویسیم. پس میتوان با کمک این دادهها و با استفاده از گراف، روابط دوستی در دانشکده را مدل کرد. هر فرد یک رأس و به ازای هر یادگاری یک رابطۀ دوستی (یک یال جهتدار) را در نظر میگیریم. حال یک گراف جهتدار بیوزن داریم. واضح است که بدون وزن در نظر گرفتن یالها فرض منطقی و معقولی در روابط دوستی نیست. اما با استفاده از این دادهها چگونه میتوان صمیمیت را مدل کرد و به وزن هر یال نسبت داد؟ تعداد کلمات؟ نسبت تعداد کلمات به بیشترین کلمات همهٔ یادگاریهای فرد؟ میزان استفاده از کلمات معنادار و خاص؟ در ادامه سعی میکنیم به این سوال اساسی در نحوهٔ ایجاد این گراف پاسخهایی بدهیم. با این حال پیش از آن و برای پاسخ دادن به سوالات دیگر بیایید کمی به خود داده و یادگاریها نگاه کنیم و با آنها بیشتر آشنا شویم.
کارهای اولیه روی دادهها
به طور دقیقتر، هر پیام یک متن، یک فرستنده و یک گیرنده دارد که فرستنده میتواند «ناشناس» نیز باشد. بنابراین در تشکیل گراف به ازای هر پیام، یک یال از فرستنده به گیرنده وصل میکنیم. اما میتوان بررسیهایی را روی دادهها بدون درنظر گرفتن گراف انجام داد.
برای مثال اینکه چه کسی بیشترین تعداد پیام را نوشته، چه کسی بیشترین تعداد پیام را دریافت کرده، بلندترین پیام چند کلمه بوده و سوالهایی از این دست که پاسخ به آنها با ابزارهای سادهای مثل groupby و sort که پکیج pandas در اختیار ما قرار داده به راحتی ممکن است. برای مثال در پاسخ به همین سوالات میلاد آقاجوهری با ۹۸ یادگاری ارسالی، روحالله سکالشفر با ۵۵ یادگاری دریافتی و یادگاری کیانوش عباسی برای آریا کوثری با ۸۹۴ کلمه رکورددار بودند.
از کارهای سادهٔ اولیه دیگر این است که ببینیم هر فرد در مجموع چند کلمه به دیگران پیام دادهاست؛ یا به طور میانگین به هر نفر چند پیام دادهاست. در شکل زیر میتوانید پراکندگی این میانگین تعداد کلمات پیامها را ببینید. محور عمودی تعداد کلمات و محور افقی تعداد افرادی است که میانگین تعداد کلماتشان برابر با مقدار عمودی است.

..
(لینک به ویکیپدیا: https://en.wikipedia.org/wiki/Tf%E2%80%93idf) TF-IDF
این عبارت مخفف Term Frequency–Inverse Document Frequency میباشد. TF-IDF یک آمار عددی است که سعی در مشخص کردن اهمیت هر کلمه در یک سری تعداد سند (document) را دارد؛ پیادهسازیهای مختلف این روش کاربرد بسیاری در امتیازدهی به کلمات در موتورهای جستجو، کتابخانهها و… دارد. این روش قصد دارد به هر عبارت از تعدادی سند وزنی نسبت دهد.
اهمیت یک کلمه رابطهای با تعداد تکرارهای آن دارد؛ بدین منظور قسمت TF از این روش، تابعی است که متناسب با تکرارهای یک عبارت در هر سند است؛ مقدار این تابع بر حسب ورودی d و t مشخص میشود که d یک سند است و t یک عبارت. یک مثال از این تابع
tf(d, t) = #t in d
است که صرفاً تعداد تکرارهای t در d را به عنوان خروجی میدهد. روشهای زیادی برای تعریف tf وجود دارد. روشی که استفاده کردیم ماژولی از Tensorflow است که تابع زیر را درنظر دارد:
tf(d, t) = (#t in d) / |d|.
قسمت دیگر از روش TF-IDF، قسمت IDF آن است. این عبارت رفتاری تقریباً مخالف با TF دارد، بدین شکل که هرچه کلمهای در سندهای بیشتری تکرار شده باشد، IDF آن کمتر میشود. برای مثال عبارت "the" در انگلیسی یا عبارت «و» در فارسی عباراتی پرتکرار ولی بدون اهمیت زیاد هستند. قصد IDF این است که امتیاز چنین عباراتی کم شود. بنابراین IDF برای یک عبارت t، تابعی معکوس بر حسب تعداد سندهایی است که t در آنها ظاهر شده باشد. یک پیادهسازی رایج از IDF عبارت زیر است
idf(D, t) = log |D| / |d\in D: t\in d|
که D مجموعهٔ همگی سندها میباشد. مجدداً پیادهسازی این تابع در Tensorflow شکل
idf(D, t) = 1 + log(|D| + 1) / (|d\in D: t\in d|)
میباشد. در نهایت، TF-IDF تابعی بر حسب ورودیهای D (کلیهٔ سندها)، d (عضوی از D) و t (یک عبارت) است و مقدار آن تعریف میشود
tf-idf(D, d, t) = tf(d, t) . idf(D, t).
اکنون tf-idf برای یک عبارت در یک سند رابطهٔ مستقیمی با میزان اهمیت آن عبارت دارد. برای اهمیت کلی یک عبارت، کافیست tf-idf آن به ازای همگی سندها جمع زده شوند؛ در ادامه از این موضوع برای یافتن کلمات مهمی که افراد در یادداشتهایشان به یکدیگر استفاده کردند بهره میبریم.
روی دادههای مسئلهTF-IDF
مقدار tf-idf را به ازای هر کلمه از بین پیامهای رد و بدلشده بین دانشجویان را محاسبه کردیم و ۱۵۰ کلمه با بیشترین tf-idf را در نمودار ابرکلمهٔ زیر نمایش دادیم:

دقت داشته باشید که tf-idf تابعی از سند میباشد؛ بنابراین کلمههای بالا نسبت به سند خود مقدار tf-idf بالا دارند؛ به عبارتی، اینها کلماتی هستند که در یادداشتی که در آن ظاهر شدهاند، بیشترین «اهمیت» را داشتهاند.
میتوان طور دیگری کلمات را دستهبندی کرد، بدین منظور به جای اینکه هر یادداشت را یک سند درنظر بگیریم، هر سند را به ازای هر فرستنده برابر با کلیهٔ یادداشتهایی بگیریم که آن فرد فرستادهاست؛ بنابراین اگر کلمهای در اینجا مقدار tf-idf بالایی داشته باشد، بدین معنی است که این کلمه در میان کلیهٔ یادداشتهای ارسالی یک فرد از «اهمیت» بالایی برخوردار بودهاست. ۲۰۰ کلمه با بیشترین tf-idf در این حالت را میتوانید در نمودار زیر ببینید:

به عنوان یک تمرین، خوب است خودتان سعی کنید این کلمات را به ازای یک شکل دیگر تعریف سندها مشاهده کنید؛ برای مثال یک روش میتواند این باشد که به ازای هر دریافتکننده، یک سند تعریف کنید که متشکل از کلیهٔ یادداشتهای دریافتی آن فرد است. در این صورت داشتن tf-idf بالا به چه معنی است؟
وزندهی یالهای گراف
در این قسمت، به دنبال آن هستیم که به دنبال پاسخ این سؤال که «در جامعهٔ دانشگاهی، آیا جنسیت یک ویژگیِ متمایزکننده بین افراد جامعه است؟» بگردیم. سعی میکنیم ابتدا گراف را بسازیم سپس با استفاده از ابزارهای embedding گراف را به فضایی برداری میبریم و در آن فضا این ویژگی را بررسی میکنیم.
برای ساخت گراف، به ازای هر فرد، یک رأس درنظر گرفته میشود. به ازای هر یادداشت، یالی جهتدار از فرستندهٔ آن پیام به دریافتکنندهاش اضافه کرده و وزن آن یال را طبق فرمول زیر تعریف میکنیم:
w(sender, receiver, text) = sqrt(|text| / max(|text| which text is sent by sender))
(به نظر شما چرا از رادیکال در این وزندهی استفاده شده است؟)
یکی از روشهای رایج بررسی خواص گراف، استفاده از embeddingهاست؛ بسیاری از روشهای رایج در یادگیری ماشین و تستها و استنتاجهای آماری در فضاهای برداری تعریف شدهاند به همین دلیل روشهایی مرسوم شدهاند که گراف (رئوس و یالها و ویژگیهای رئوس و یالها) را ورودی میگیرند و بازنماییای از رئوس یا یالهای این گراف در یک فضای برداری را خروجی میدهند که برای مثال رئوس شبیه به هم یا همسایه فاصلهٔ اقلیدسی کمی دارند. یکی از این روشها استفاده از کتابخانهٔ node2vec است. ابتدا یک مدل از node2vec با ۲ بُعد را روی این دادههای این گراف fit کردیم. به ازای هر فرستندهٔ پیام، این ۲ بُعد را تخصیص دادیم. نمایش افراد بر اساس این ۲ بُعد را به همراه جنسیت آنها میتوانید ببینید:

در نمودار بالا، x بعد اول فضای برداری node2vec است و y بعد دوم. به سادگی میتوان دید که با داشتن گراف، جنسیت افراد با استفاده از مؤلفهٔ x به خوبی قابلیت جداسازی دارند.
مجدداً کارهای مشابه را تکرار کردیم، این دفعه node2vec را ۱۰ بُعدی درنظر گرفتیم. سپس برای هر فرد featureهای مربوط به این ۱۰ بُعد را تخصیص دادیم؛ در نهایت PCA این ۱۰ feature را برای تمامی افراد حساب کردیم. PCA روشی برای کاهش ابعاد فضاهای برداری با بعد بالاست. در نمودار زیر، میتوانید جداسازی افراد را بر حسب x، مؤلفهٔ اول PCA و y، مؤلفهٔ دوم آن ببینید:

مجدداً به نظر میرسد مؤلفهٔ x به تنهایی به شکل خوبی جداسازی را انجام دادهاست. برای تأیید بیشتر این موضوع میتوانید جداسازی افراد را براساس مؤلفهٔ دوم (y) و سوم (z) نیز ببینید:

که به شکل خوبی جداسازی صورت نگرفتهاست.
در این بخش با استفاده از یک روش embedding مشاهده کردیم که صرفا با داشتن گراف روابط و دوستیها جنسیت افراد متمایزکننده آنهاست. به نظر شما چه ویژگیهای دیگری (مانند المپیادی یا کنکوری بودن) متمایزکنندهٔ ما دانشجویان هستند؟ آیا مانند بحث جنسیت، دادههای واقعی نیز این ادعا را پشتیبانی میکنند؟
ببینیم این گراف چه شکلی است!
خب در این بخش میخواهیم خیلی مختصر و ابتدایی به خود این گراف نگاهی بیندازیم و شاید هم کمی با بقیه گرافهای اجتماعی آن را مقایسه کنیم. اول گراف را بکشیم ببینیم چه شکلی است!


برای کمی سادهتر شدن تعریفها(و گذشتن از تقصیر آن راسهای دور گراف که هیچ یادگاریای ننوشتهاند و فقط یادگاری گرفتهاند!) اگر یالها را بدون جهت در نظر بگیریم به گراف سمت راست میرسیم. در این گراف ۱۲۵ راس و ۲۰۶۱ یال دارد. همانطور که حدس میزدیم گراف یک گراف همبند است؛ که یعنی از هر راسی به راسی دیگر مسیر وجود دارد. قطر(diameter) گراف برابر ۳ است؛ که یعنی بزرگترین فاصله(فاصله بین ۲ راس را طول کوتاهترین مسیر از یکی به دیگری تعریف میکنیم) در گراف برابر ۳ است و هر راس حداکثر با ۳ یال به همهی راسهای دیگر وصل میشود. همچنین میانگین فاصله در گراف ۱.۷۶ است؛ که البته از خیلی قدیمالایام که در تلاش بودهاند گرافهای دنیای واقعی را مدل کنند1 یا آزمایش کنند2 میانگین فاصله در گرافهای اجتماعی ((O(log(n در نظر گرفته میشود که اینجا هم با توجه به تعداد راسها منطقی است.
حالا بیاییم دو توزیع معروف را در این گراف ببینیم. ابتدا توزیع درجه راسها را بکشیم.


همانطور که میبینید هر دو در حدود درجه ۲۰ یک قله دارند و توزیع outDeg فشردگی بیشتری دارد و قله آن کمی عقبتر است(از این مقایسه چه برداشتی میتوانید بکنیم؟). البته اگر نگاهی به توزیع درجه در بعضی گرافهای اجتماعی(برای مثال گراف شبکه اجتماعی flickr 3 و یا گراف اینترنت 4) بیندازیم میبینیم که معمولا توزیع درجه در این گرافها از توزیع توانی(power-law) پیروی میکند؛ که در اینجا به دلیل کوچک بودن گراف ما خیلی این رفتار مشاهده نمیشود.
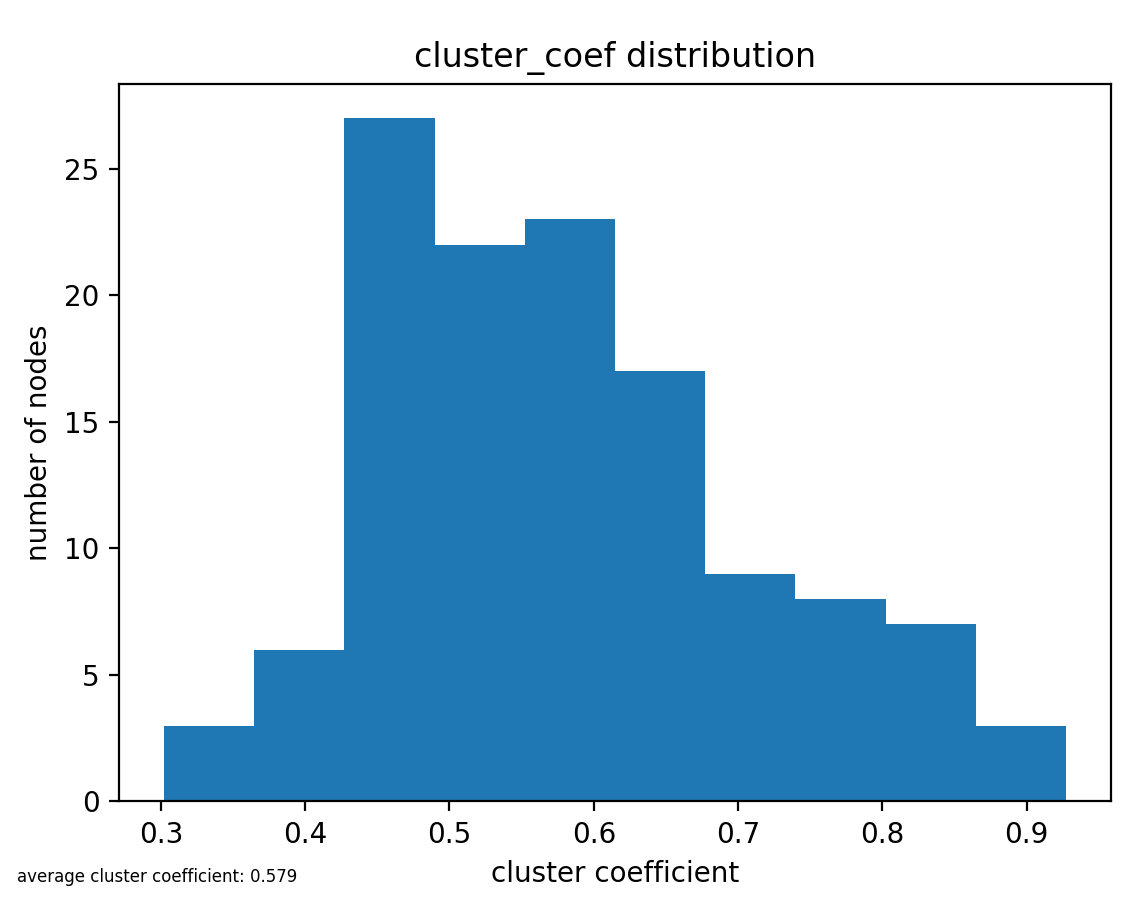
به عنوان آخرین مشخصه نیز بیایید به عنوان یک متغیر برای اندازهگیری میزان متصل بودن اعضای هر خوشه به یکدیگر توزیع ضریب خوشهبندی(cluster coefficient) را در گراف خود ببینیم. ضریب خوشهبندی یک متغیر برای هر راس تعریف میشود که معرف این است که راسهایی که این راس به آنها متصل است چقدر به یکدیگر متصل هستند. به عبارت خودمونیتر به این معنی که اگر من یک راس باشم چه کسری از دوستهای من که به آنها وصل هستم با همدیگر دوست هستند و اجتماعی که من مرکز آن هستم چقدر اجتماع به هم متصلی است. این ضریب به شکل
ci=2ei/ki(ki-1)
است که e تعداد یالهای بین همسایههای راس مورد نظر i و k درجهی راس i است. همانطور که میبینید در گراف ما میانگین ضریب خوشهبندی همهی راسها برابر 0.579 است که برای مثال در مقایسه با گراف شبکه اجتماعی مربوط به MSN که دارای میانگین ضریب خوشهبندی 0.179 است4 بسیار ارتباطات بین راسهای همسایه هر راس بیشتر است که به نسبت جامعه کوچک دانشکده منطقی به نظر میرسد.
ما در این بخش سعی کردیم برای نمونه چند تحلیل ابتدایی در این گراف انجام دهیم؛ در ادامه اگر کسی حال بیشتری برای تحلیل این شبکه داشتهباشد بسیار کارهای دیگری میتواند انجام دهد که مثلا یکی از آنها پیدا کردن موتیفهای دوستی و ارتباط در این شبکه است. یا برای مثال خوشهبندی و پیدا کردن اجتماعها در این گراف یکی دیگر از کارها است.(که البته ما تلاش کردیم با یک الگوریتم حریصانه(louvain community detection) این کار را انجام دهیم که همانطور که در زیر میبینید و از شکل گراف میشد حدس زد خیلی چیز خوبی از آب در نیامد!)

جمعبندی
در این متن، سعی کردیم با دادهورزی روی دادههای جشن فارغالتحصیلی دانشجویان ۹۴ به چند سوال ساده مثل اینکه چه کسی بیشترین پیام را دریافت کرده یا نوشته، چه کلماتی بین یادگاریها رایجتر بوده و آیا جنسیت ویژگی متمایزکننده بین دانشجویان است پاسخ دهیم. سوالات دیگری هم بود مانند اینکه آیا میتوان نوع یادگاریها را دستهبندی کردی که روشهای ما نتوانست به آن پاسخ معناداری بدهد. به نظر شما با داشتن این دادهها، به چه سوالات دیگری میتوان پاسخ داد؟ روشی که ما در این متن پیش گرفتیم چه اشکالاتی داشت؟ آیا ادعای شهودیای که بر اساس یک نمودار کردیم پشتوانهٔ آماری هم دارد؟
ما هر روز در ارتباط با دنیای اطرافمان در محیط دانشگاه دادههای جدیدی از حضور و غیاب و چک کردن سایت درس تا رزرو و روزخرید غذا تولید میکنیم که اگر با عینک ریزبینانهٔ علومداده به آنها نگاه کنیم، میتوانند پاسخ سوالات جالب و حتی مهمی از زندگی اجتماعی را در خود داشته باشند.
(برای دسترسی به این داده و کد نوشته شده برای آن با دبیر علمی رایانش ارتباط بگیرید.)
1 https://www.renyi.hu/~p_erdos/1959-11.pdf
2 https://snap.stanford.edu/class/cs224w-readings/travers69smallworld.pdf
3 https://cs.stanford.edu/people/jure/pubs/microEvol-kdd08.pdf
4 https://cs.stanford.edu/people/jure/pubs/msn-www08.pdf
